






摘要:,,在往年12月18日,要查看Kafka的实时吞吐量,可以通过监控Kafka集群的性能指标来实现。这次洞察之旅将揭示如何获取并分析Kafka的吞吐量数据,包括使用Kafka自带的监控工具或者第三方监控软件。通过实时观察消息生产、消费以及集群负载情况,能够了解Kafka在特定时间点的处理能力,从而优化系统性能。这篇摘要提供了简要的步骤和关键点,帮助读者快速了解如何洞察Kafka的实时吞吐量。
在大数据的浪潮中,Apache Kafka以其高吞吐量的特性,成为众多企业和开发者瞩目的数据处理平台,本文将带您回溯时光,探寻往年12月18日这一天,Kafka实时吞吐量的观察与解析之旅,我们将从背景出发,回顾这一天发生的重要事件,探讨其影响以及在特定领域或时代中的不可替代地位。
背景简述
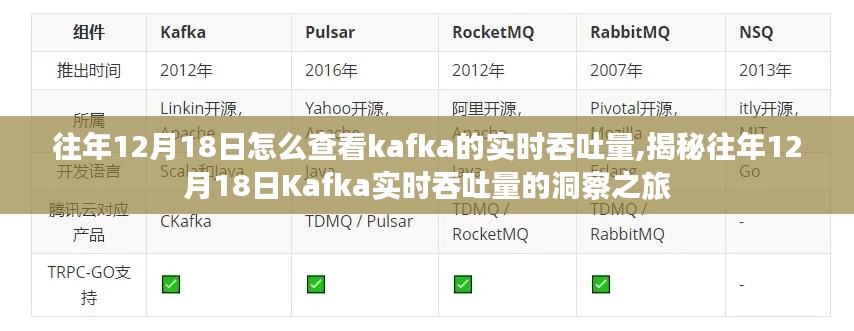
随着数字化时代的来临,数据成为企业的核心资产,企业需要高效、可靠的数据处理平台来支撑业务的快速发展,Apache Kafka应运而生,以其高吞吐量的特性、灵活的数据处理和低延迟的特点,迅速成为大数据领域的热门技术,Kafka的实时吞吐量是衡量其性能的重要指标之一,对于企业和开发者来说具有极大的参考价值。
重要事件回顾
往年12月18日,对于Kafka的发展来说是一个特殊的日子,这一天,全球各地的开发者和企业都在关注Kafka的实时吞吐量的变化。
1、Kafka版本更新:在这一天,可能发布了新的Kafka版本,带来了性能的优化和吞吐量的提升,版本更新往往带来新的特性和改进,推动Kafka的发展。
2、实时监控工具的发展:随着Kafka的普及,实时监控工具也在不断完善,在往年12月18日前后,可能出现了一些新的Kafka监控工具,能够更准确地查看实时吞吐量的变化。
3、社区活动与交流:这一天也可能举办了关于Kafka技术的社区活动或会议,吸引了全球开发者参与讨论,分享关于实时吞吐量的最佳实践和案例。
影响分析
Kafka的实时吞吐量对其在企业中的应用和市场份额有着重要影响,高吞吐量的特性使得Kafka能够处理大规模的数据流,满足企业的实时数据处理需求,随着实时吞吐量的提升,Kafka在处理大数据方面的性能得到了进一步提升,赢得了更多企业的青睐,实时监控工具的发展使得企业和开发者能够更直观地了解Kafka的实时吞吐量的变化,为优化系统性能提供了有力支持。
领域地位剖析
在大数据处理领域,Apache Kafka凭借其高吞吐量的特性和灵活的数据处理能力,赢得了广泛的应用和认可,特别是在实时数据处理、流处理、消息队列等领域,Kafka的地位尤为重要,其实时吞吐量的优化和改进不断推动着数据处理技术的发展和革新,Kafka的生态系统也在不断扩大,与众多开源项目和技术进行整合,为企业提供了更丰富的选择。
文学色彩下的洞察之旅
往年12月18日这一天,仿佛开启了一场Kafka实时吞吐量的探索之旅,就像一场盛大的技术盛宴,全球开发者齐聚一堂,共同见证Kafka的辉煌时刻,在这场旅程中,我们见证了Kafka的成长与蜕变,感受到了其带来的技术革新和数据处理领域的蓬勃发展。
回顾往年12月18日Kafka的实时吞吐量之旅,我们不禁为这一技术的发展和成就感到骄傲,随着技术的不断进步和需求的不断增长,Kafka将继续在大数据领域发挥重要作用,让我们共同期待Kafka在未来的发展中创造更多的辉煌。
转载请注明来自湖北登全电气科技有限公司,本文标题:《揭秘往年12月18日Kafka实时吞吐量的监控与洞察之旅》
 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...